
各インデックスの特徴や実行計画の見方について言及しています!
学習教材・参考
絵で見てわかるSQLServerの仕組み
第5章「行ストア型テーブル」でインデックスについて詳しい解説がありオススメです。
達人に学ぶDB設計 徹底指南章
達人に学ぶDB設計 徹底指南章 を読んでみた感想や1部内容紹介をしているので是非読んでみてください!
達人に学ぶDB設計 徹底指南章 を読んでみた感想
-

-
【書籍紹介】達人に学ぶDB設計 徹底指南章 を読んでみた感想
達人に学ぶDB設計 徹底指南章 というDB書籍を読んだ感想や重要だと思った箇所をピックアップしてご紹介します!

動画だと、ピーコックアンダーソン という方のUdemy講座がハンズオンで学べてわかりやすいです!

↓は私の先輩エンジニアの記事です。インデックス以外にも色々と書かれていて、とても勉強になることが多いです。主に私の記事ではMacでの説明が多くなりますが、Windowsでの説明が見たい場合や他の観点で情報が得たい場合は是非見てみてください!

SQL Server のインストール
それぞれ以下のリンク先の参照をお願いします。
Windows環境
DBサーバ:SQL Server
DBクライアントツール:SQL Server Management Studio(日本語版)
Mac環境
DBサーバ:Docker 上にSQL Serverのコンテナ作成
DBクライアントツール:Azure Data Studio
概要
前提、仮定
テストデータとして、以下の様なテーブル・データがある前提として解説していきます。データ量が少ないとインデックスが効かずテーブルを全件検索するような処理になることもあるのである程度のデータ量が必要になります。
-- ---------------------
-- 取引
-- ---------------------
CREATE TABLE blog.sales (
sales_id INT NOT NULL
, amount INT NOT NULL
, transaction_date DATE NOT NULL
, status VARCHAR(20) NOT NULL
, cancel_flg BIT NOT NULL
, shop_id INT NOT NULL
, user_id INT NOT NULL
, PRIMARY KEY(sales_id)
, FOREIGN KEY(user_id) REFERENCES blog.my_user(user_id) -- ユーザテーブルがある前提
, FOREIGN KEY(shop_id) REFERENCES blog.shop(shop_id) -- 店舗テーブルがある前提
)
・取引(sales)データ
5,000万件データあり、取引日は「2022-01-01」〜「2022-12-31」の間で、かつステータスは99%以上が「成功」である。
※ ステータス:成功、失敗の2種
上記のような数千万件のデータをインサート文作りながら手動で用意するのは大変です。大量データを用意するには、BCPコマンドが有効で、以下の記事も参照お願いします!
BCPコマンドについて
-
-
【SQL Server】BCPコマンドで大量データ一括インポート!
2025/10/12 DB, SQL Server
SQL Serverへ大量データを一括で入れ込むためのコマンドラインツールであるBCPコマンドについて解説します!

実行計画を表示する方法
実行計画はSQL Serverがどのようにデータを取得しにいっているかを示したものになります。以下で解説するのは、Azure Data Studioでの見方になります。「Include Actual Plan」を押下し「Exclued Actual Plan」になった後に、「Estimated Plan」というを押下すると実行計画がプレビューでグラフィカルに表示されます。日本語化プラグインを入れていると「説明」という文言になっています。

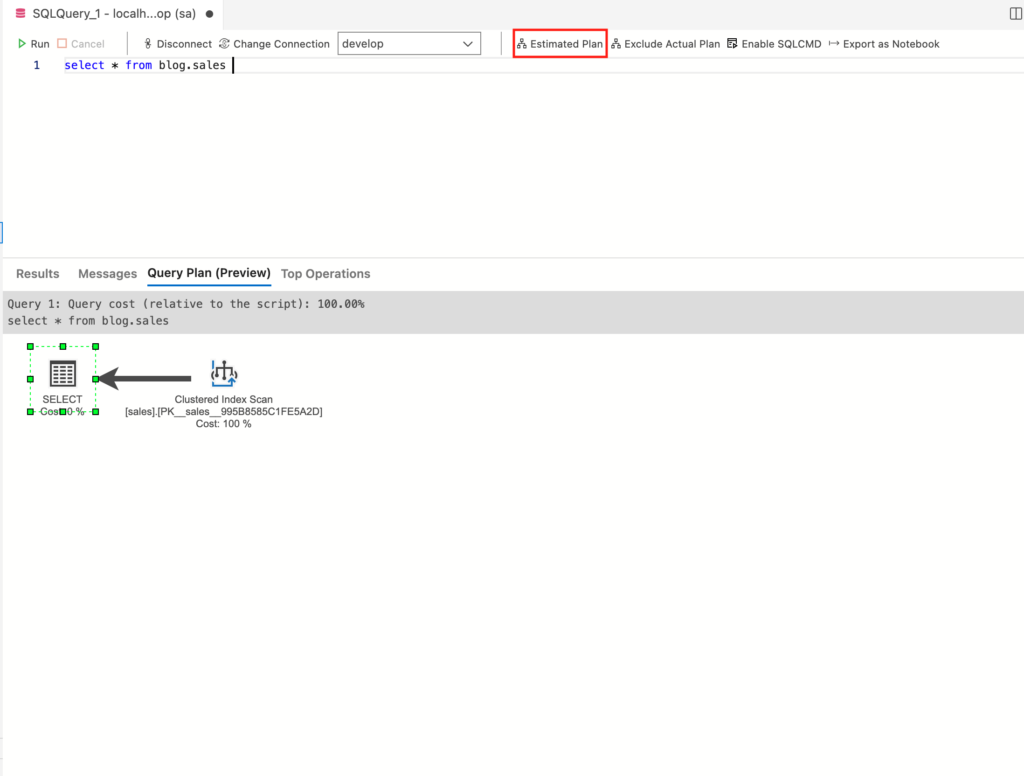
プレビューでは取得したxmlをグラフィカルに表示しているので、xmlを保存する事もできます。その際に、拡張子を.sqlplanとして保存すると、Azure Data Studioでファイルを開いた際にプレビューしてくれます(.xmlだと文字で表示)。クエリストアやスロークエリのチェックで実行計画を取得した際には、拡張子を変えて保存する必要があります。

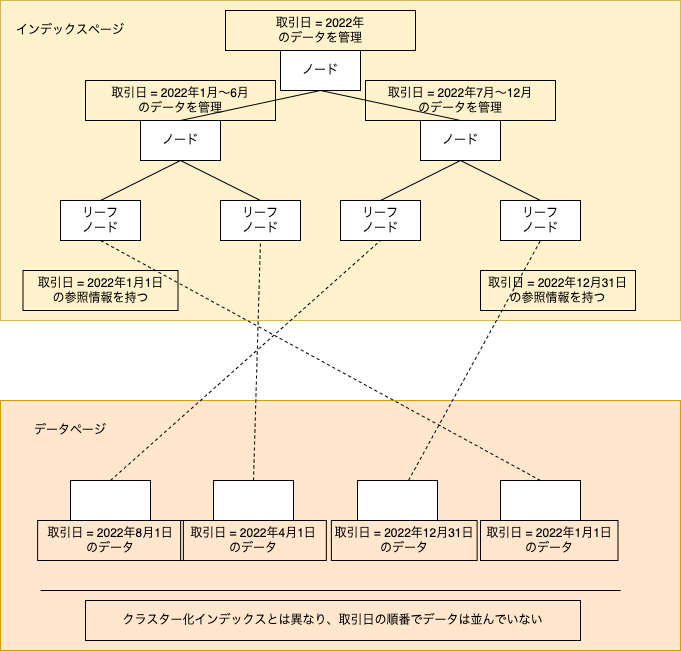
SQL Serverのデータ構造について
インデックスの説明に入る前に、SQL Serverにおけるインデックス関連のデータ構造について言及します。実際のデータはデータページ、インデックスはインデックスページという領域にそれぞれ格納されています。インデックスによる検索をする場合は、インデックスページの各ノードを辿りリーフノードへ到達してから、Key Lookup(キー参照)やRID Lookup(RID参照)により実際のデータを取得します。
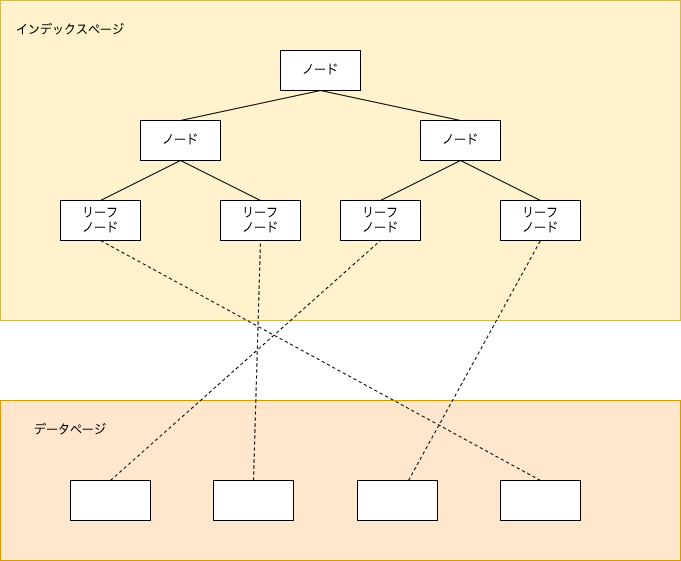
データページとは別にデータ容量が必要になるため、最適なインデックスを最適な数だけ設定することが重要です。
インデックスが効かないとどうなるか
まだインデックスを作成していない取引データに対して検索をかけてみると、実行計画は以下の様になります。(プライマリーキーがあると、クラスター化インデックスが作成されてしまうのでここだけプライマリーキー外して検索した場合の画像となります)
select *
from blog.sales
where transaction_date = '2022-01-01'
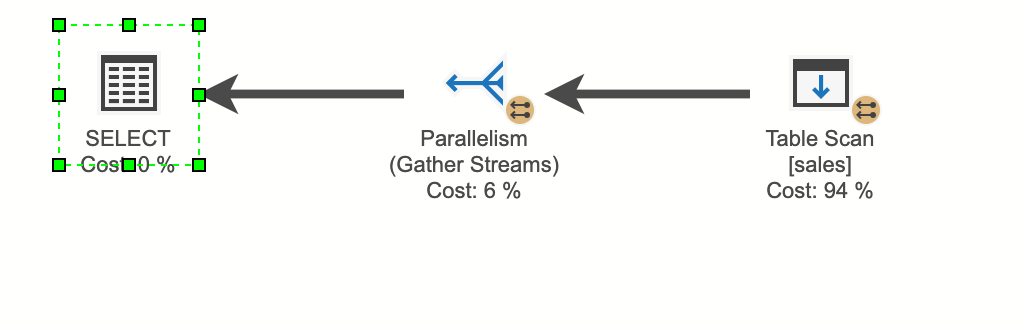
「Table Scan」はテーブルの全件を参照していることを意味します。取引日の条件指定をしても、SQL Serverからすると、どこにどの取引日のデータがあるかを把握できないため、テーブルの全件を参照する必要があります。また、仮に一意にレコードを特定するような条件で検索したとしても、インデックスがない状態ではSQL Server としては一意に決まるかどうかは認識できないため、全件参照した上でデータを取得します。Scanは最も遅い動作なので、件数の少ないマスタデータ以外などでは、Scanにならないようにインデックスをチューニングすることが望ましいです。
注意点
一度検索したデータはキャッシュされて2回目以降の実施時に高速になる可能性があります。検証する際はキャッシュクリアしつつ実施することをオススメします。
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
インデックスの種類
インデックスにはクラスター化インデックスと非クラスター化インデックスの大きく分けて2種類のインデックスがあります。それぞれ特性が異なるので、以下で解説します。
クラスター化インデックス
テーブルに対して1つだけ設定でき、最も高速な検索を実現するインデックスです。リーフノードにデータページが格納されているため、インデックスページからデータページへのアクセスをする必要がなく、インデックスページを辿ることでデータを取得できます。インデックスを設定したキーの順番通りにデータが物理的に並ぶため、テーブルに1つしか作成することはできません。
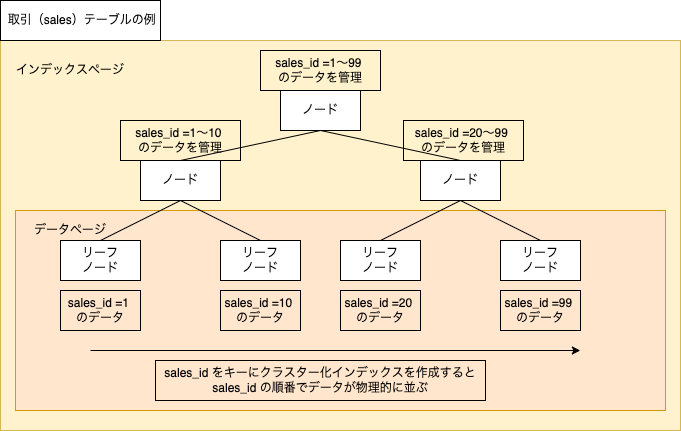
クラスター化インデックスの作成方法は、プライマリーキーを作成する or 以下のようにDDLでインデックスを作成します(WindowsだとツールでGUIからも作れたりします)。
CREATE CLUSTERED INDEX clustered_index ON blog.sales (sales_id);
5,000万件のデータがある状態でも、クラスター化インデックスを指定のキーで検索した場合は一瞬でデータ取得が可能です。クラスター化インデックスが効いている場合は、「Clustered Index Seek」という表示になります。Seek というのがインデックスが効いている証拠です。

クラスター化インデックスのキー以外で検索を実施すると、Scanになる場合があります。クラスター化インデックスが作成されているテーブルでは、「Table Scan」とは表示されず「Clsutered Index Scan」と表示されます。ぱっと見ではインデックスが効いているようにも見えますが、「Table Scan」とほぼ同等で遅い検索になります。
select *
from blog.sales
where transaction_date = '2022-01-01'

まとめると以下のような特徴があります。
- 最も高速な検索ができる
- テーブルに1つしか作成できない
- キーの順番で物理的にデータが並ぶ
- リーフノードにデータが存在する(Lookupしない)
- プライマリーキーにセットしたキーはクラスター化インデックスのキーとなる
- クラスター化インデックスがない状態のでScan:Table Scan
- クラスター化インデックスがある状態のでScan:Clustered Index Scan
非クラスター化インデックス
テーブルに複数の作成できるインデックスで、インデックスページを辿った後にデータページへアクセスしデータを取得するインデックスです。主にこちらのインデックスをチューニングすることが多いかと思います。
取引テーブルのステータスカラムをキーにインデックスを作成するDDLは以下のようになります。「NONCLUSTERED」はなくても非クラスター化インデックスとなります(上の例では取引日カラムの例ですが、うまいこと実行計画が想定通りにならなかったため、ステータスカラムで説明させていだきます)。
CREATE INDEX IX_sales_01 ON blog.sales(status); -- または、 CREATE NONCLUSTERED INDEX IX_sales_01 ON blog.sales(status);
ステータスカラムでの検索をインデックス作成前後で比較してみます。
select *
from blog.sales
where status = 'failure'
インデックス作成前
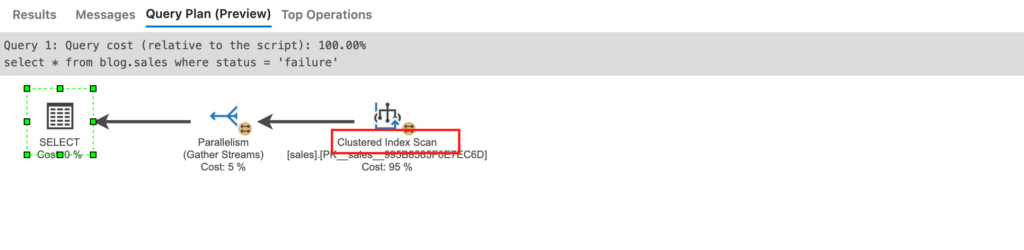
インデックス作成後

インデックス作成後ですと、「Index Seek」となりインデックスが効いていることがわかります。また、「Key Lookup」とあるのでインデックスページを辿った後に、データページへアクセスしていることがわかります。
Lookupの方法は、テーブルにクラスター化インデックスがある場合とない場合異なります。クラスター化インデックスがない状態では、RID Lookup(ポインタ参照)といって、データページのポインタをリーフノードに持ち、データを取得しにいきます。クラスター化インデックスがある状態では、Key Lookup(キー参照)といって、リーフノードにはクラスター化インデックスのキー情報を持ち、データページへデータ取得しにいきます。
ただし、このLookupは意外とコストが高くインデックスが効いているのに、思ったよりも性能が出ないことがあります(画像の例ですが、Index Seekが17% / Key Lookupが83%であることからもデータページへのアクセスコストは高いことがわかります)。この場合に有効なのが次に説明する付加列インデックスになります。
Lookupにより性能が出ない場合は付加列インデックスを使用することを検討しましょう。
非クラスター化インデックスについてのまとめ
- テーブルに1つしか作成できない
- インデックスページを辿った後にデータページを参照する
- クラスター化インデックスがない状態ので参照:RID Lookup(ポインタ参照)
- クラスター化インデックスがある状態ので参照:Key Lookup(キー参照)
付加列インデックス
非クラスターインデックスの拡張版インデックスで、特定のカラムをSELECTする場合に有効なインデックスになります。内部構造としては、インデックスページのリーフノードに特定のカラムのデータを持たせるというものです。基本的にインデックスページにはキーになるカラムのデータしか持ちませんが、追加でSELECTしたいカラムがある場合にデータを2重持ちさせるような方法になります。
特定のカラムでなく*で全カラムを取得する場合(通常の非クラスター化インデックス)
select *
from blog.sales
where status = 'failure'
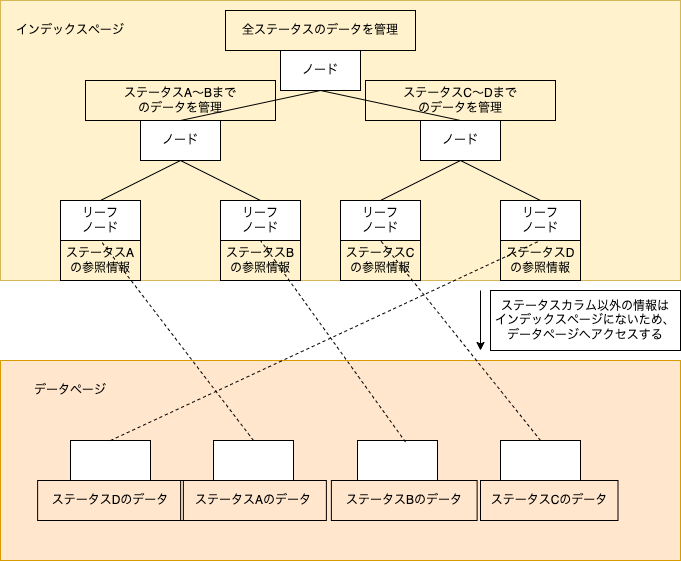
上記の例では全てのカラムを取得するような検索でしたが、ステータス・取引ID・ユーザIDだけが必要な場合と仮定します。この場合は付加列(INCLUDE句)に取引IDとユーザIDを含めることでLookupせずにデータ取得することができます。
付加列インデックスのDDLは以下のようになります。
CREATE INDEX IX_sales_02 ON blog.sales(status) INCLUDE(sales_id,user_id);
各ノードには、ON句に指定した検索条件となるキーカラム(この場合、ステータス)の情報はあります。リーフノードにのみ特定のカラム(この場合、取引ID / ユーザID)を追加して、データページとデータを2重持ちにすることで、Lookupすることなく高速な検索を実現します。
各ノードに持たせずリーフノードにだけ持たせるというのがミソです。全てのノードに必要なカラムを持たせるの(ON句にカラム指定)はカバリングインデックスと言い、付加列インデックスよりも高速になりますが、データ容量をより必要とするため、デメリットが大きくなります。高速な検索をしつつ、カバリングインデックスよりもデータ容量を節約できるのが付加列インデックスになります。
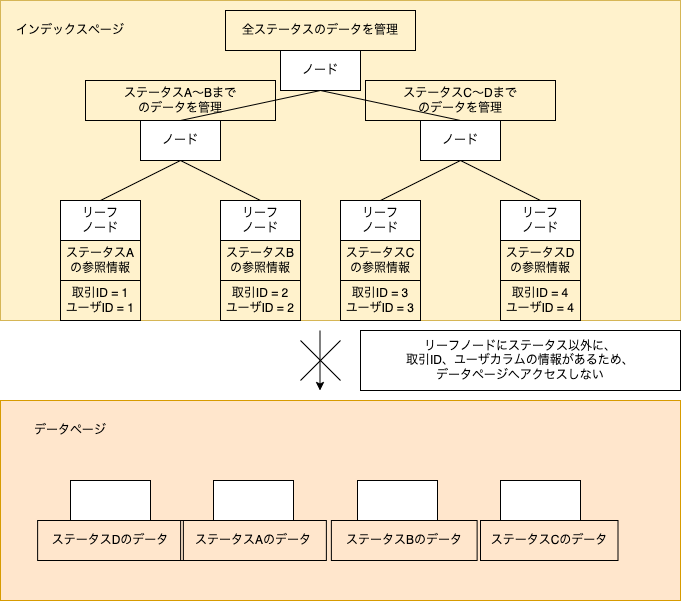
特定のカラムのみをSELECTするようなクエリを実行すると、
select sales_id,user_id,status
from blog.sales
where status = 'failure'
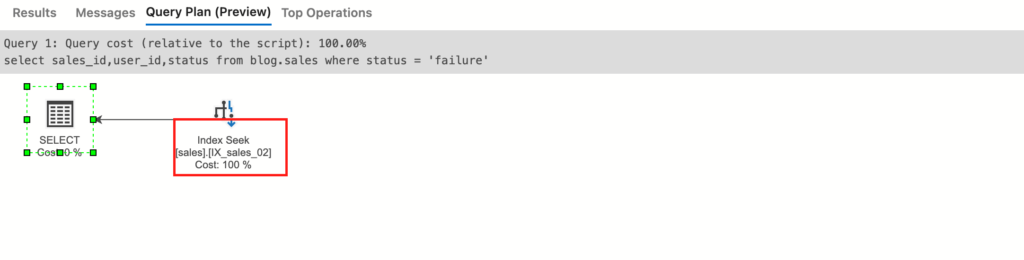
「Key Lookup」がなくなり「Index Seek」のみの実行計画で、データページへのアクセスがなくなっていることがわかります。
だたし、前述の通り付加列インデックスはデータページとデータを2重持ちになるため、更新系の処理が更に遅くなります。そのため無闇にINCLUDEするのではなく、最低限必要なカラムを選択することが重要になります。また、INCLUDEに指定したカラム以外を1つでもSELECTするとLookupしてしまいます。
付加列インデックスのまとめ
- 非クラスター化インデックスの拡張版
- リーフノードにのみ付加列(INCLUDE)したデータを持つ
- 付加列に指定したデータのみを参照する場合はデータページへ参照しないため高速
まとめ
SQL Serverの内部構造と実行計画の基本的な読み方を抑えた上で、用途に合わせてインデックスを使い分けることが重要です。クラスター化インデックスは1つしか作成できないので、無闇にプライマリーキーをセットするのではなく、実用的なキーにセットすることが求められます。また、インデックスは作成すればするほど更新系の処理が遅くなるため、最適なインデックスを最適な数だけ作成することも、チューニングする上では考慮しなければなりません。
実際に性能改善にてSQL Serverを用いたバッチ処理の改善内容についても以下の記事で言及しているので、是非読んでみてください!
性能改善について
-
-
【SQL Server】性能改善で感じた重要なこと!
2024/1/5 DB, SQL Server
業務で行ったバッチ処理を性能改善した際に感じた重要なことについて発信しています!
