
達人に学ぶDB設計 徹底指南章 を読んでみた感想に、体験談や加えて自分で追加で調べた内容を含め発信していきます。
達人に学ぶDB設計 徹底指南書
論理設計と物理設計
ファイルの物理配置
DBは単一のファイルではなく複数種類のファイルから作成されています。DBにより構成は異なりますが、概念として以下の種類のファイルがあることを認識しておくべきです。
- データファイル
- インデックスファイル
- システムファイル
- 一時ファイル
- ログファイル
一時ファイル(一時テーブル)は、サブクエリの展開やGROUP BYやDISTINCTなどを使用した際に一時的なデータを保存するファイルで、永続化されるようなデータではありません。 業務で経験しましたが、結合の多いクエリの際に、途中段階で明示的に一時テーブルを使用するようにし、必要なカラムのみSELECTして処理するとメモリが開放されて、性能改善できる場合があります。
ログファイルはDBへの変更内容を保存しており、ロールバックやリストアする際に使用されるファイルになります。DBは変更を受付した際にデータを直ぐに変更するのではなく、まずはログファイルに書き込んでからデータの更新を行います。
バックアップ設計
データのバックアップ之種類は大きく分けて以下の3つです。
- フルバックアップ
- 差分バックアップ
- 増分バックアップ
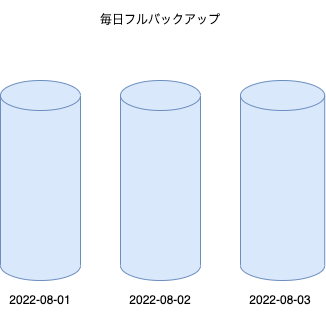
フルバックアップ
全てのデータを毎回バックアップする方法です。復元したいタイミングのバックアップを使用すればいいだけなので運用が簡単ではありますが、性能面やコスト面でのデメリットも大きいです。
メリット
・運用がともてシンプルになる。
デメリット
・バックアップ時間が長い。
・データ容量を多く消費する。
・サービス停止が必要な場合がある。
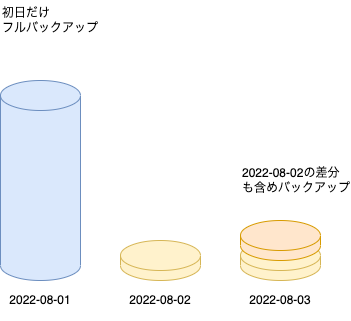
差分バックアップ
バックアップ周期の初日のみフルバックアップし、以降は前日分も含め(初日分以外)バックアップする方法です。毎日フルバックアップするのと比較してデータ容量の消費が少ないですが、復元の手順は少し増えます。例の「2022-08-03」のデータを復元するには、「2022-08-03」と「2022-08-03」のファイルが必要です。
メリット(フルバックアップとの比較)
・バックアップ時間が短い。
・データ容量の消費が少ない。
デメリット(フルバックアップとの比較)
・バックアップする際のファイルが2つ必要となる。
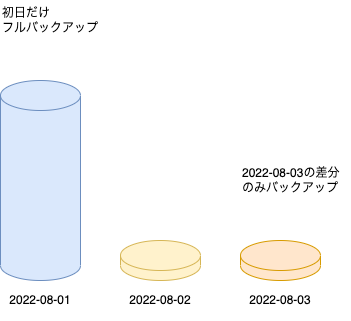
増分バックアップ
差分バックアップの更に拡張した方法で、前日分を含めず純粋に当日分のみをバックアップする方法です。例の「2022-08-03」のデータを復元するには、「2022-08-01」、「2022-08-02」、「2022-08-03」のファイルが必要になります。
メリット(差分バックアップとの比較)
・バックアップ時間が短い。
・データ容量の消費が少ない。
デメリット(差分バックアップとの比較)
・バックアップする際のファイルがかなり多くなる(日数分など)。
この様に、バックアップ取得時のコストとリカバリ時のコストがかなりトレードオフな関係にあることがわかります。業務要件に合わせて、バックアップ作成にかけて良い時間、復元するのにかけて良い時間などを考慮して検討する必要があります。一般的には、差分バックアップまたは増分バックアップが多いようです。また、当日分の更新も復元する必要があるため、ログファイルからロールフォーワードする必要があります。
ただし、クラウドのDBを使用している場合はあまり意識しなくて良いかもしれません。マネージドサービスも多くなってきていて、クラウドで任意の断面を復元させることがポータル上で簡単にできたりします。
論理設計と正規化
テーブル名の命名規則
テーブルは何かしらの共通点を持ったデータの集合なので、テーブル名は複数形や複数名詞できるような名称にすべきです。名称を決めた後に一度振り返ってみて、適切な名称かどうかチェックしてみることが必要です。
キー
あまり普段は意識しないですが、候補キー・スーパーキーについてメモします。
候補キー
レコードを一意に特定できるカラム(orカラムの組み合わせ)のことです。テーブルの中に複数存在する可能性がありますが、その中から主キーは選択されます。
スーパーキー
候補キーに非キーのカラムを付加した場合のカラムの組み合わせのことで、候補キーの数よりも多くなります。
制約
NOT NULL 制約や一意性制約はよく使用しますが、チェック制約は使ったことがないためメモします。
チェック制約
文字通り値をチェックするような制約です。SQL Serverだと以下の様に カラムに制約を追加できます。チェックに合格しないインサート文やアップデート文は実行するとエラーとなります。
ALTER TABLE <スキーマ名>.<テーブル名>
ADD <カラム名> int NULL
CONSTRAINT <チェック名>
CHECK (<カラム> > 100 AND <カラム> < 1000); -- チェック内容は例
GO
高次正規形
基本的には第3正規形までで十分ではありますが、それ以上の正規化があり内容については割愛で、概念としてあることだけ認識しておくといいと思います。
- ボイスーコッド正規形
- 第4正規形
- 第5正規形
常に正規化すべきか
基本的には第3正規形まで行い、データの冗長性を排除してあげることが必要です。ただ、私が携わったプロダクトでは、データを取込んだ断面のマスタ情報を非正規化しながらデータ作成していました。これは、性能面を考慮すると共に、取込み断面のマスタ情報を記録するためという仕様上の理由もあります。基本的には正規化をする前提ですが、最終手段として非正規化するというのも手段の1つと言えると思います。
ER図
あえて書くほどでもないですが、読み方をたまに忘れてしまうので、備忘的に書いてみます。カーディナリティは覚えておきたい単語です。
カーディナリティ
ER図においては、エンティティ間の多重度を示します。
テーブルにおいての意味は、カラムに含まれるデータ値のバリエーションの多さを示します。カーディナリティが高いというのは、バリエーションが多いことを示し、カーディナリティが低いというのはバリエーションが少ないことを示します。
ER図はA5M2というDBクライアントツールから生成したり、diagrams.netで作成するのがやりやすいですね。今回はdiagrams.netで作ってみました。
IE表記法
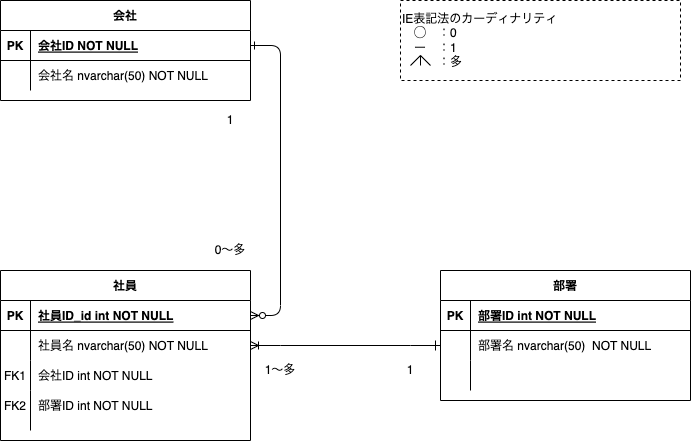
IDEF1X
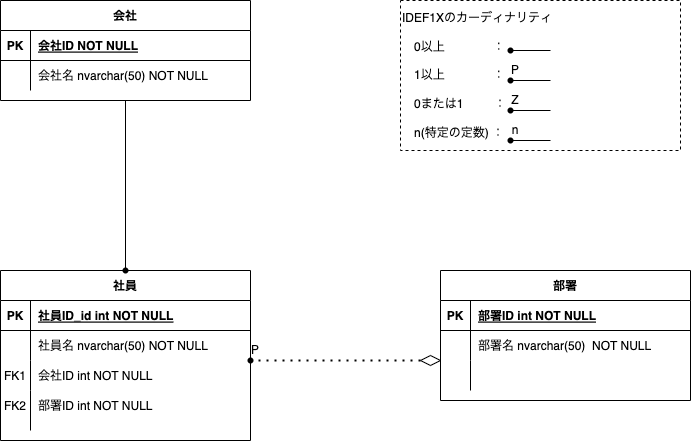
多対多のテーブル
以下の様な多対多の関係となるテーブルについては、関連実体としてそれぞれのIDで複合キーとした紐付けテーブルを作成すると、多対多の関係を解消することができます。
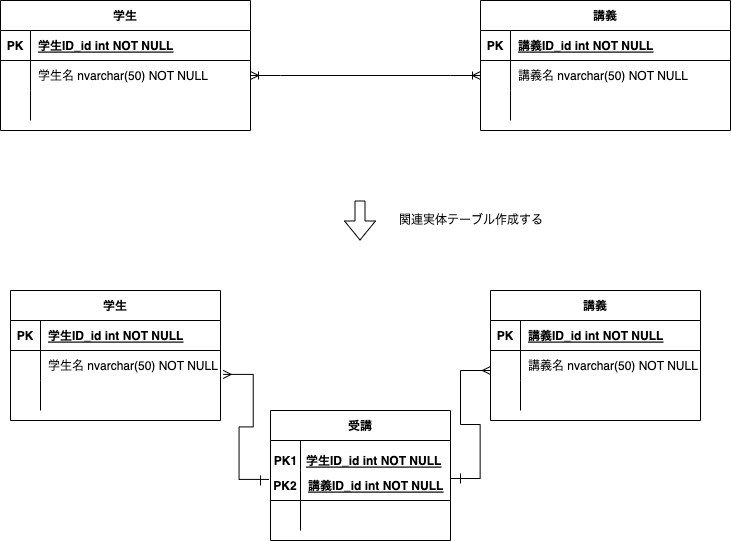
性能
インデックス
アプリケーション透過的、データ透過的は覚えておきたい単語として解説しておきます。
アプリケーション透過的
アプリケーションからは意識しなくてよいということです。どのインデックスを使用するかは基本的にはDBMSに委ねます。
データ透過的
インデックスを作成してもデータに影響を与えないということです。
インデックスは主に以下の様な種類があります。
- B-treeインデックス
- ビットマップインデックス
- ハッシュインデックス
主にはB-treeインデックスの特徴を理解しておく必要があります。端的に言うとバランスが良いということです。
- 平衡木のため、どの値を取得するにもコスト同じ
- データ数が大量になっても検索にかかる時間の増加が緩やか
- 挿入・更新・削除にかかるコストが検索と同程度
- 不等号や範囲検索にも対応
- 暗黙的なソート
平衡木のため、どの値を取得するにも同じコスト
B-treeインデックスのイメージ
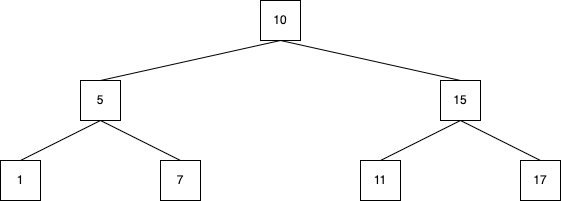
データ数が大量になっても検索にかかる時間の増加が緩やか
計算量のイメージ
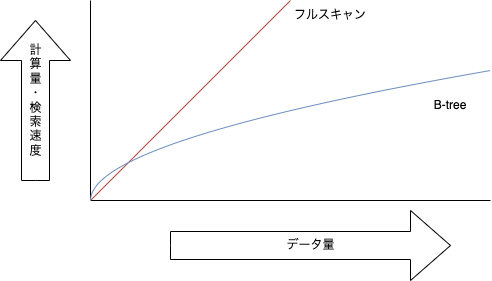
暗黙的なソート
以下の様な処理の場合には暗黙的にソートがされている。
- 集計関数
- 集合演算子
- OLAP関数
- ORDER BY
インデックスの作成方針は以下の様な観点に合致する場合に作成すべきです。
- 大規模テーブル
- カーディナリティの高いカラム
- 検索条件、結合条件になるカラム
カーディナリティの高いカラムに作成
カーディナリティが高いほどデータの絞り込み率が高くなり、インデックスの効果が大きくなります。データを1/3にしか絞り込めない条件と1/30に絞り込める条件であれば、後者の方が有効なインデックスであると言えます。またカーディナリティが高くても特定の値にデータが集中している場合も、絞り込みが効かずインデックスの効果が発行されない場合があります。
インデックスが効かないのは以下の様なシーンです。
- インデックス列で演算や関数を使用
- IS NULLで検索
- 否定形(NOT条件)を使用
- OR条件を使用(IN句を使用すべき)
- 後方一致、中間一致による曖昧検索(前方一致ならばOK)
- 暗黙的に型変換
その他の注意点としては、断片化という現象があります。データの挿入や更新により、内部的なデータの持ち方が効率的でなくなり、性能が落ちることがあります。私が携わったプロダクトでも、定期的にインデックスの再構築を行って断片化を解消していました。
個別のDBMSについての発信ですが、SQL Serverのインデックスについて発信しているので是非読んでみてください!SQL ServerもB-treeインデックスで構成されています。
SQL Serverのインデックスについて
-

-
【SQL Server】インデックスと実行計画について解説!
2024/1/5 DB, SQL Server
SQL Serverの各インデックスの特徴や実行計画の見方など、性能チューニングするにあたり基本的なことについて言及しています!

統計情報
テーブルやインデックスなどのサマリ情報です。DBMSのオプティマイザは統計情報を参照し、実行計画を決定します。統計情報が実際のテーブルと乖離してしまうと適切な実行計画が選択されない場外もあります。そのため、自動更新する設定をするなどの対応が必要になります。
アンチパターン
かなり初歩的な内容も含め紹介がありますが、全体的に言えることは抽象度を高めてはいけないということです。
非スカラ値
配列型などを使用した場合に1カラムに複数データを入れることができます。第1正規形にもなっておらず、RDBの根本を覆す様な使用方法になるため、絶対に回避すべきです。
| 学生ID | 名前 | 家族の名前 |
|---|---|---|
| 1 | 佐藤 次郎 | 三郎 |
| 2 | 田中 太郎 | 康介 四郎 |
| 3 | 高橋 公平 | 健二 浩二 泰史 |
ダブルミーニング
カラムは変数ではないため、1カラムで複数の意味を持たせるべきではないです。以下の様なテーブルで、4カラム目に学年が4年生の場合だけ残単位数を格納するような場合は、残単位のためのカラムを増やすべきです。
| 学生ID | 名前 | 学年 | 取得単位?残単位? |
|---|---|---|---|
| 1 | 佐藤 次郎 | 1 | 100 |
| 2 | 田中 太郎 | 2 | 80 |
| 3 | 高橋 公平 | 4 | 10 |
単一参照テーブル
同じ様な意味合い・構成の2つのテーブルを1つに統合してしまうのは、レコードが多くなり性能が落ちたり、テーブルとしての意味合いがぶれてしまう可能性があります。
| 学生ID | 名前 | 選考 |
|---|---|---|
| 1 | 佐藤 次郎 | 19 |
| 2 | 田中 太郎 | 20 |
| 3 | 高橋 公平 | 22 |
| 教授ID | 名前 | 年齢 |
|---|---|---|
| 101 | 飯田 和男 | 43 |
| 102 | 佐々木 洋平 | 50 |
| 103 | 吉田 純平 | 39 |
↓に統合
| ID | 名前 | 年齢 |
|---|---|---|
| 1 | 佐藤 次郎 | 19 |
| 2 | 田中 太郎 | 20 |
| 3 | 高橋 公平 | 22 |
| 101 | 飯田 和男 | 43 |
| 102 | 佐々木 洋平 | 50 |
| 103 | 吉田 純平 | 39 |
もしこの様に統合するのであれば、タイプを持たせるなどの工夫が必要です。
テーブル分割
水平分割はレコード単位にテーブルを分割する行為です。
| ID | 名前 | 年齢 |
|---|---|---|
| 1 | 佐藤 次郎 | 19 |
| 2 | 田中 太郎 | 20 |
| 3 | 高橋 公平 | 22 |
| 4 | 東谷 洋平 | 22 |
| 5 | 坂本 修一 | 21 |
| 6 | 伊藤 裕太 | 22 |
↓IDで分割
| 学生ID | 名前 | 年齢 |
|---|---|---|
| 1 | 佐藤 次郎 | 19 |
| 2 | 田中 太郎 | 20 |
| 3 | 高橋 公平 | 22 |
| 学生ID | 名前 | 年齢 |
|---|---|---|
| 4 | 東谷 洋平 | 22 |
| 5 | 坂本 修一 | 21 |
| 6 | 伊藤 裕太 | 22 |
IDでテーブルの参照先を変えるのは大変で、運用コストが高まります。パーティション化を行うことで物理的にファイルを分けることができ、性能改善することができます。アプリからは1つのテーブルとしてしか認識せずに済むので、アプリケーション透過的であることを保証できます。
垂直分割はレコードではなく、カラムで分割する方法です。こちらも性能を意識し、実施される手段ではありますが、垂直分割と同様に運用コストが高くなります。
不適切なキー
同じ意味を持つキーは、テーブルが異なっても同じ型にすべきです。特に外部キーは結合によく使うので型には注意です。型が異なると結合した際に暗黙的に型変換されてしまい、結合が遅くなる可能性があります。
まとめ
本記事で紹介した内容以外にも、グレーなノウハウについてや、更に踏み込んだ設計についても解説されています。また、演習問題もあります。DBに関わる前に読んでもあまりピンとこないこともありますが、DBで実務をこなした後に後に再度読み返してみるとかなり理解が深まったりします。いろんな観点が網羅的に散りばめられ、図解も多くわかりやすいので、とてもオススメな書籍です!
SQL Serverを使用したバッチの性能改善内容についても記事を書いているので是非読んでみてください!
性能改善について
-
-
【SQL Server】性能改善で感じた重要なこと!
2024/1/5 DB, SQL Server
業務で行ったバッチ処理を性能改善した際に感じた重要なことについて発信しています!
